2022过年这几天在家没啥事儿干,发现阿里的ECS比自己用的云虚拟主机要便宜很多。于是就顺手买了几年的。结果没成想,这一顺手,就把三个节假日搭了进去,期间徒手码了近500条命令才算基本告一段落。
我一直对于写些Google能搜索到的东西没有任何兴趣。但是这三天实际操作下来,发现网上搜索到的资料,当时也许对,但是时至今日,没有一个到现在还是正确而且合理的。
在此,首先感谢开源社区过去10年的卓越贡献,让10年前的实操层面的知识基本都报废了。也让我有动力把这三天的琐碎点滴重新记录下来。感觉写得再啰嗦点,大概就能出书了,《7天精通WordPress迁移——基于CentOS 8、Apache 2.4和MySQL 8》。(尽管我也知道,10年后,本文很可能也没有什么参考价值了。)
I Hear and I Forget, I See and I Remember, I Do and I Understand.
—— 《荀子·儒效》
第一日
服务器到手就是一台祼机,除了自带的CentOS以外,什么都没有。
职业程序员干活第一步,先Google了一下“WordPress迁移”找别人的作业打小抄。找到的比较全的是一个知乎专栏文章《WordPress 搬家方法总结:迁移主机和更换域名》,里面介绍了一个叫All-in-one的插件。看上去自己什么都不用干,只要点点就可以搞定。这很好。
但是走到第二步就卡住了。因为步骤里说:在新主机空间上安装好 WordPress,进入后台安装 All-in-One WP Migration。
得,还是得先自己安装WordPress喽?作为一位不专业的客户,我的期望是,你都叫All-in-one了,居然连自动安装WordPress这么基本的工作都没做。如果我在新主机上,都已经安装好了WordPress,我要你干啥?我为啥不用……我找找……啊,这个WordPress自带的导出功能?

不过转念一想,不对,如果WordPress已经做得够好了,为啥还会有人写插件呢?而且还是成立了一家公司做WordPress迁移服务!这里一定是大坑啊。
官方功能介绍,都只介绍了它能做什么,做好了什么。
然而,它不能做什么,没做好什么,才更值得关注。
—— Hugo Gu
看上面的“导出”功能介绍是看不出什么的了。于是我只能自己试下,也就点下“下载导出的文件”的事儿嘛。
然后眼看着这个文件,一秒钟就下载下来了,我有就种不祥的预感,这特么肯定缺东西啊。但是鬼知道你缺什么啊?你让我肉眼看吗?我看了眼下载下来的XML文件大小,460KB,这肯定没有图片啊。打开简单看了一眼,果然只有文本,图片都是URL地址。好么,这意思是我还要自己再手工导图片?也行,但是更大的问题是:除了图片还有没有别的缺的?
不过无论用哪种方式,看上去我都得自己安装WordPress。我一开始一直没有想法自己安装WordPress,是因为安装WordPress这件事儿,并不是点个exe文件或是跑个yum install这好了。而是至少得安装这些东西:
- Apache HTTPD:Web服务器。
- PHP:运行WordPress的脚本语言。世界上最NB的编程语言。(BTW,我还不会。)
- MySQL 或 MariaDB:WordPress的数据都是存在这里的。
- WordPress:撰写、发布博客的网站。
然后你为了做管理,可能还得安装下面这些东西。
- vsftpd: 一个FTP服务器,可以用于管理Web Server里的内容。
- phpMyAdmin: 一个MySQL的Web管理页面。(你看PHP的NB之处就在于此,人家都不叫MySQLAdmin,而要叫phpXXXX,仅仅是因为用PHP写的。)
而且按Linux服务的风格,这些东西不大会是安装好了就可以直接用的。
大家都知道自己用WordPress搭个博客网站不是个十分简单的事儿,所以WordPress自己干脆商业化了,自己官方没有任何文档介绍如何自己用WordPress搭博客(原来是有的,现在全删除了。),只给了个建站手册详细介绍了把WordPress搭好需要注意的各种事项(大概是用来劝退要自建的小白之用),然后自己官方网站隆重推出一键搭博客,每个月30块到500块不等。有兴趣的同学可以去官网了解(需要科学上网)。这一个月30,一年至少360,而且还是功能受限版本,全功能一年6000块。一台虚拟主机也就200多,什么功能都有,作为一名程序员,不仅手痒痒,也肉疼。
另外,微软这里,居然有一篇写于2020年5月的,在IIS上安装WordPress的教程。但是其版的落后程度让人瞠目结舌。

这里又要补充一句,阿里云,在买ECS的时候,可以指定默认安装哪个镜像,其中就有很多WordPress镜像,为啥不直接用呢?主要原因还是一样的,因为我不知道这镜像缺什么,其次就是现有的镜像的OS和PHP和WP的版本都比较老。安装好了一样要升级一轮。而且买了服务器,如果只搭个博客,肯定是浪费了。
说干就干。
先从Web服务装起,WordPress 官方支持的有Apache HTTP和nginx。那我们到底用哪个呢?主要的考量点有两个:功能和性能。考虑个人博客一般对性能要求不高,而且一般Web服务器上的性能问题都可以通过水平扩展的方式解决,然功能问题一般都得靠人才能解决,所以一般而言:功能远比性能重要。
网上不难找到性能测评结果,从其中一篇来看,单就WordPress来看,Apache 2.4的性能相比2.2已经有了大幅度的提高,已经接近nginx。而进一步的性能提升,大都会依赖合理地添加缓存,而非Web Server本身的性能优势。说来也是,都是走的FastCGI体系,性能能差多少呢?瓶颈就算有,主要也会是在PHP上。不然WordPress也不会强烈建议用户把PHP升级到7.4以便获得最多几倍的性能提升了。
目前找到的,会影响WordPress使用的,Apache HTTP和nginx的功能上的差别就是文件夹级配置。Apache HTTP支持通过每个文件夹中的.htaccess文件来控制Web Server的行为,但是nginx并没有类似的能力支持。于是WordPress的permalinks,在Apache HTTP上,可以通过自动生成.htaccess文件的方式得到支持(当然,需要配置开启AllowOverride)。但是在nginx上,就必须也要同步修改nginx的配置文件才能生效。从软件工程最佳实践的角度,这违反了功能正交性的基本原则。了解到这一个差别,基本就让我一票否决了nginx。(这里我要再补充一下,以防有人把这句话的覆盖面放大这里“一票否决了nginx”仅限于个人WordPress建站场景。至于各大公司,服务压力大,要把每个节点性能发挥到极致,同时也有实力搞一整套工具做配置管理。用啥都可以。只要规章制度流程健全,贯彻实施到位,用哪个其实都OK。这个问题其实非常有争议,如果你有兴趣,可以在这里加入圣战。)
安装HttpD还是很简单的。
dnf install httpd httpd-manual mod_ssl mod_perl mod_auth_mysql至于后面那些mod是干啥的,不要问,问就是开源社区常识。然后启动:
systemctl start httpd.service一个Web服务就好了。但是啥东西都没有,主页都没有。
然后在安装MySQL之前又卡住了,我们到底是安装MySQL呢?还是MariaDB呢?老的服务是MySQL的,虽然MariaDB其实就是从MySQL分出来的,而且从开源血统上讲,比MySQL的还纯正。好,我们来做个更细致的比较吧,拿别人的作业直接看结果吧。总结一下如下表:
| MySQL | MariaDB | |
| 优势 | 高性能、高可用 事务支持 | 向后兼容 开源 基于 MySQL 社区版 新引擎 (PBXT, XtraDB, Maria, FederatedX) |
| 劣势 | 难以扩展 Oracle买了,使用上有限制 不适合超大数据 | 新引擎,谁也不知道后面会发生什么。 就像所有的开源引擎一样,没有技术支持。 |
想想还是MySQL,看上去MariaDB为了不让Oracle有解题发挥过河拆桥的空间,把引擎都给换了。那就不靠谱了。我喜欢折腾,但是不喜欢在正经事儿上折腾。所以当然是MySQL了。
分析完了,安装其实很简单。
dnf install @mysql #安装
systemctl start mysqld.service #启动
systemctl enable mysqld #开启自动启动
mysql_secure_installation #配置
mysql -u root -p #联上去之后需要手工创建给WordPress用的数据库。(这里假设你看得懂SQL)
mysql> CREATE DATABASE wordpress;
mysql> CREATE USER `admin`@`localhost` IDENTIFIED BY 'pass';
mysql> GRANT ALL ON wordpress.* TO `admin`@`localhost`;
mysql> FLUSH PRIVILEGES;
mysql> exitMySQL安装及配置完毕。下面轮到PHP了。
dnf install php php-fpm php-opcache php-gd php-curl php-mysqlnd php-json php-intl php-xml php-pear php-devel
systemctl enable --now php-fpm网上多数介绍安装的文章,不会一开始就安装这么多东西,但是这些东西WordPress的基本功能就是需要的。所以一次性安装好就好了。比如xml、intl、pear、devel这些一开始可以不安装,但是你会发现WordPress管理后台首页上就会有功能加载不了,同时健康检查也会说有很多框架缺失。(后文会有介绍,当然,如果你按这个命令做,就不会再遇到后文的那些问题了。)
然后下载wordpress的安装包。
curl https://wordpress.org/latest.tar.gz --output wordpress.tar.gz下了半天下载不下来。速度只有1K/s的样子。然后还下5分钟就断了,然后还没有自动断点续传。我猜这是因为WordPress这个网站不在大局域网里,而且大概率也没做CDN。这个时候,我脑子里冒出三个选择:
- 无限重试。
- 在服务器上安装个类似迅雷的玩意。
- 考虑到我本地和服务器之间的网速还行,我可以在本地下载下来,然后想办法上传到服务器上去。
我思考了几秒钟选了方案三。于是又多了一个事儿。就是如何从本地把文件发到ECS服务器上去。
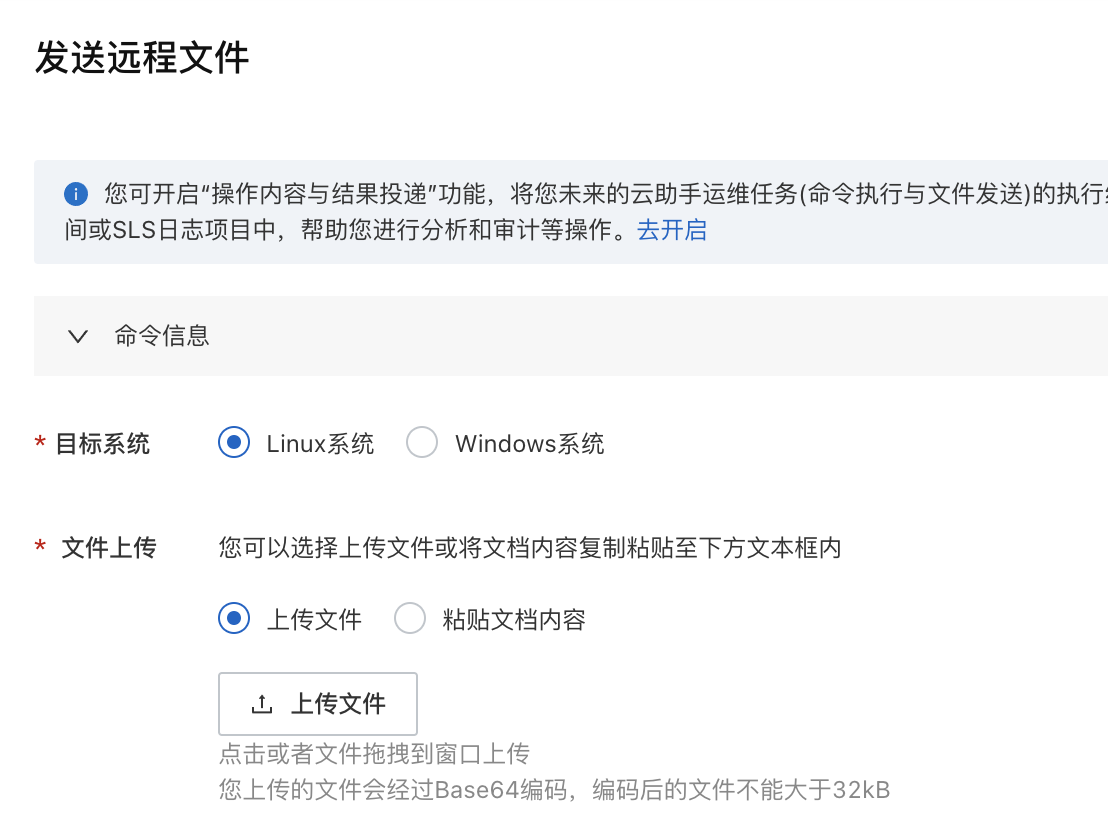
先是在ECS的网站上找有没有官方支持的功能,找到了一个“发送文件”的功能,刚想夸夸阿里,结果一打开就发现这也太渣了,最大32KB。
算了,还是用最土的办法吧。直接SSH发。第一步先把本地的SSH Key注册到ECS服务器:
本地把pub key复制到剪切板:
pbcopy < .ssh/id_rsa.pub然后再在服务器上把key写到~/.ssh/authorized_keys里。
为了方便登录,在本地的~/.ssh/config里加上如下配置。
host aliyun-host
HostName <IP of the Host>
Port 22
IdentityFile ~/.ssh/id_rsa
PasswordAuthentication no
User <Username to login>然后就可以这样从本地登录到ECS服务器了。
ssh aliyun-host然后就可以用下面的命令把本地文件上传到服务器的用户目录上了。
scp wordpress.tar.gz aliyun-host:~写了3000多字,终于来到了激动人心的,本来要做的正事儿,WordPress安装环节。步骤也很简单。(主要参考了这里。)
tar xf wordpress.tar.gz
cp -r wordpress /var/www/html这里,网上有些文章会提示说,要登到主机上手工修改wp-config.php文件,把数据库的用户名密码配置上去。其实完全是多余的,WordPress早就可以在界面上配置了。在打开网站之前,需要在ECS的安全组规则中,打开80端口。

然后直接打开网站就好。http://SERVER-HOST-NAME/wordpress。按提示配置数据库链接就好。(这里其实就不太对了,如果只是建立个博客,多数人会希望用 http://SERVER-HOST-NAME/ 访问,这个后面会介绍做法。)更一般地讲:任何登录到服务器上做的手工配置文件变更,都应该避免。
就这样,一个空的新的WordPress站建好了。这是第一日。