PHP是世界上最好的语言[1]。
——有人说
编程语言层面上的东西根本不是重点,把基本功打好,学一门新的语言就是信手拈来。
——又有人说
这俩梗好老。
——我说
引言
上一篇文章《从开平方说说写代码应该考虑的事儿》讨论了如何熟悉并利用领域知识和计算机知识编写更高质量代码。这一篇也是从一个非常简单的编程问题开始,通过分析针对这个问题的不同实现方式,阐释学习一门语言都要学些什么以及怎么样才算熟悉了一门语言。
注:本文无意嘲讽《21天精通XXXX》系列,毕竟或许还是有人可以做到的,尤其是在现在这种有人只要用过就敢妄称精通的大环境下。本文只是想说明一些显而易见却又被人熟视无睹的事实。
一个简单的问题
不少人可能毕业之后就从来没写过哪怕排序之类的基本算法,这很正常,但是没人用不到各类Containers(Collections)。而且,但凡是代码写得足够多又不勤于复制粘贴的懒人,就少不得写些工具类把一些常用操作独立出来。比如这样一个函数:
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
}
我常常拿这个简单的函数当面试题,基本没有人猜不出来这个函数是要干什么,倒是会有个别人表示不知道前面的<T>是干什么用的。有性子急的可能很迅速地就构思出了如下实现,然后下一秒就发现坑在哪儿了。(简洁起见,本文所有代码略去参数为null之类的边界检查):
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
for (int index : indexes) {
if (index < list.size())
list.remove(index);
}
return list;
}
代码 1
显然上面的代码结果是不正确的。我们下面就来一步步地分析,看这个函数在Java里应该如何实现,都有哪些坑。主要意图是在这个过程体会,怎样才是充分地并合理地利用一个语言本身的理念与机制去解决问题。我也建议各位看官也先想一想自己心中的答案是什么再往下看。
先说需求到底是什么?
一说到“正确”,一说到“方案”,不少有经验的程序员的标准回答就是“看情况(It depends)”。看什么情况?看到底是要解决什么问题。我曾经也很喜欢这样回答问题,听上去多特么严谨。但是有时候这么说就不合适了,比如面试的时候这么回答就是犯傻,把到手的按自己能力方向展开并引导面试节奏的机会拱手还给了面试官。知道什么情况就说什么。没有具体上下文,要么自己假设一个;要么说自己的实现方式为了通用起见,所以牺牲了这些、这些、这些。即使不是面试,也不要说“看情况”,除非你真打算把情况一一列举出来并分情况讨论,你乐意说可能听的人也没耐心听,因为问问题的人一般只需要其中一个情况,你不嫌累,听者也会嫌烦。
回到问题上来。所以这个函数的需求是什么?需求就是函数签名所描述的那些。就像Array.Sort,它需要知道具体被使用的环境吗?它只要做到最好就是了。
函数签名能告诉你的,并不仅仅是行为,而且可以有实现细节。比如:
- 它是一个泛型函数:这大概是一个Util方法。
- 它返回一List<T>:所以它应该生成一个新的List<T>,意思应该是不要动参数List。
- 下标集合也是List:所以可能有重复,要处理。
等等。
正确性
代码1的问题是,它没有意识到删除了一个元素之后,后面的元素的下标就都变了,而且没有处理参数下标重复的问题。(还有别的问题后面再讨论)
于是一个简单的改进就可以同时解决上面的两个问题。
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
Collections.sort(indexes);
for (int i = indexes.size() - 1; i >= 0; i++) {
final int index = indexes.get(i);
if (index < list.size())
list.remove(index);
}
return list;
}
代码 2
这个没什么难的,所有人都可以做到这一步。遗憾的是不少人走到这一步就不再走了。因为它已经是正确的了(如果先不考虑对参数的改动)。我不知道是不是因为喝了Bert Lance那句“If it ain’t broke, don’t fix it.”毒鸡汤,并成功解释成了“如果它没坏,就不要改进它,不要重构它,不要动它!而且我也只能做到这里了!”
正常情况下,如果并不需要复杂设计与编码就可以做到O(n)的函数,还是不要一开始就写成O($$n^2$$)的好吧?代码写成这样,好意思在文件头上留下自己的名字么?(要不要加是另一回事儿。)
线性时间复杂度
在上面的代码基上,一个可以提高性能的改进是这样的:把要排除的元素标记成null。然后找出不是null的元素。
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
for (final int index : indexes) {
list.set(index, null);
}
final List<T> result = new ArrayList<>();
for (final T value : list) {
if (value != null)
result.add(value);
}
return result;
}
代码 3
这个代码有两个问题:
- 性能还不是O(n)。
- 显然如果参数list里本来就有null就不行了。
问题1后面会展开讨论。对于问题2,理论上,可以用一个自己私有的对象实例代替null。
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
final T DELETE_MARKER = new T(); // Compile Error
for (final int index : indexes) {
list.set(index, DELETE_MARKER);
}
final List<T> result = new ArrayList<>(list.size());
for (final T value : list) {
if (value != DELETE_MARKER)
result.add(value);
}
return result;
}
代码 4
但是很可惜的是,由于Java的类型擦除机制,类似上面的方式在Java里是不可行的,因为T在运行时不存在。想知道T是什么?在Java里你得多传一个Class参数进来。而C#里上面的代码是可行的(当然需要额外泛型约束才能编译通过,但那不是重点,重点是C#可以知道T具体是什么)。
既然这种方式遇到了些障碍。我们就换一个思路:这个函数一共就俩参数,不for这个就只能for那个。(如果你解决问题真是这么个思路还是不要当程序员了。)
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
final List <T> result = new LinkedList<>();
for (int i = 0; i < list.size(); i++) {
if (!indexes.contains(i)) {
result.add(list.get(i));
}
}
return result;
}
代码 5
代码5的结果正确,但是性能又退化成O(log(n))或O($$n^2$$)了。想想,为什么是有“或”?为什么有两种情况?
通用性(独立于参数实现)
请思考如下几个问题:
- list.contains的复杂度是多少?
- list.get的复杂度是多少?
List的某些操作的时间复杂度取决于其实现方式,甚至还会依赖于调用者的使用模式。对于JDK中常见的几个List实现,在本文的使用方式下,他们的理论上的时间复杂度会是这个样子的(有没有哪个跟算法书上说的不一样?请想想为什么):
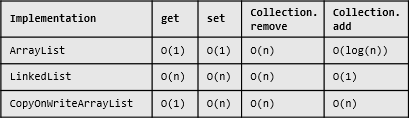
图1
也就是说,代码5的时间复杂度会依赖于传入参数的类型。这显然不够理想。有没有办法让这个函数的运行效率无关参数类型呢?
问题1出在List的contains方法上,无论在哪种实现方式下,它都是O(n)复杂度的。好像无解啊?那有没有什么Container的contains方法是O(1)的?当然有啊:
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
final List <T> result = new LinkedList<>();
final Set<Integer> indexesSet = new HashSet<>(indexes);
for (int i = 0; i < list.size(); i++) {
if (!indexesSet.contains(i)) {
result.add(list.get(i));
}
}
return result;
}
代码 6
问题2出在get操作上,LinkedList的get慢,但是ArrayList的get是O(1)的啊。所以心够宽的话,大不了可以先把整个list复制到一个新的ArrayList里不就结了?没错,但是那代码太美我不敢贴上来。那有没有别的方法呢?想一想现在的情形:我们无论如何是要遍历整个list,而且应该只需要遍历一遍。
这明明就是Iterator的地盘啊。所以用iterator就好了啊。
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
int index = -1;
final Iterator<T> iterator = list.iterator();
final Set<Integer> indexesSet = new HashSet<>(indexes);
final List<T> result = new LinkedList<>();
while (iterator.hasNext()) {
final T item = iterator.next();
index++;
if (!indexesSet.contains(index))
result.add(item);
}
return result;
}
代码 7
有经验的程序员其实一开始想的就是这个方法。这就是有经验的程序员和菜鸟的差距。到这一步,这个函数在功能上性能上都达到了预期的要求,而且做到了不依赖具体参数类型。面试的时候,如果有人能在15分钟内做到这一步,我就已经很高兴了。
但是,本文的重点要讲的,还没有开始。上面只是热身:熟悉问题本身。
正题才刚刚开始:那都是Java代码吗?
上面的确都是Java代码,因为它们都符合Java 8语言规范啊,能编译,能运行。但是不觉得有什么问题么?就这么简单的一个问题,怎么需要这么多代码呢?感觉什么地方不太对啊。
感觉不对是因为,这种代码,也不是Java,这是几乎所有OO编程语言及其框架的公共子集。它没有充分利用Java Collections Framework所提供的各类机制,上面的那些代码,放在C#里,放在Python里,放在C++里,仅仅需要修改一下语法和类名就可以同样地正确工作起来。如果学一种语言只是学到这门语言的这样的公共语言部分,其实就可以解决所有编程问题,不再学习任何新的语言点也能写出所有需要写的代码来,只是写起来就像上面一样——繁复。学一门语言,如果只是学到这种“公共子集”程度,的确是可以“一通百通”,信手拈来,几个小时学完。但是这离学会那门语言,还差得很远。
本文要实现的这个函数,大概算是最普通的编程问题了,它所涉及的,是几乎每个Java程序员天天都要使用到的东西。也就是JCF的那些接口,那些类。我说上面的代码没有充分利用Java,所以我们看看JCF的三个主要接口里都有些什么?请仔细看一遍下面两张图,有没有哪个函数名让你眼前一亮或是一头雾水的感觉呢?各位看官看这些方法的时候请思考下面几个问题:
- 了解这些API的用法,是否需要依赖工作上的项目提供特别的机会?
- 你觉得需要几年的工作经验才能让一个人知道并能在合适的时候正确地使用这些函数?
- 知道这些函数的使用,算熟悉Java?精通Java?还是没有直接关系?

图 2
图中,绿色高亮的是Java 8新引入的接口。黄色高亮部分是辅助性函数,就是那种你完全不知道、不使用,也能无障碍地写出Java代码的函数。没高亮的函数,是必须要有的,也必然会用到的,也是那种每个人都不得不知道的,所谓的语言公共子集部分。当然,如果有人说他连remove方法都用不着,或是说从来只用iterator,我也并不觉得奇怪。
充分利用Java
我们看到List接口里有个比较特别的ListIterator或许不是所有人都知道。我们也来看看这个ListIterator和Iterator比有什么特别的地方。注意:ListIterator继承Iterator。

图3
所以稍微对Java多熟悉一些,就可以知道,从ListIterator是可以在遍历一个List的过程中知道当前index而不需要自己维护一个index变量的。于是我们的代码可以简化成:
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
final ListIterator<T> iterator = list.listIterator();
final Set<Integer> indexesSet = new HashSet<>(indexes);
final List<T> result = new LinkedList<>();
while(iterator.hasNext()) {
if (!indexesSet.contains(iterator.nextIndex())) {
result.add(iterator.next());
}
}
return result;
}
代码 8
如果用Java 8,那也可以通过新的removeIf来实现(想想这个函数线程安全吗?):
private static int index = -1;
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
index = 0;
final Set<Integer> indexesSet = new HashSet<>(indexes);
final List<T> result = new LinkedList<>(list);
result.removeIf(t -> !indexesSet.contains(index++));
return result;
}
代码 9
如果喜欢用Stream呢,还可以写成这样:
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
final Set<Integer> indexesSet = new HashSet<>(indexes);
return range(0, list.size())
.filter(i -> !indexesSet.contains(i))
.mapToObj(list::get)
.collect(toList());
}
代码 10
然而不幸的是,这个代码又出性能问题了。因为它依赖了输入参数list的get方法。在前面的代码中,我们说过,总是可以把list先Copy到一个新的ArrayList中。但是如果传入参数本来就是ArrayList就是多余的了。所以要么就先检查一下参数类型是instanceof ArrayList不就结了?但是如果参数是个自定义的List呢?要不要先给参数做个Quick Perf测试来侦测其get方法是不是O(1)的再来决定要不要先Copy到ArrayList中呢?
在一个成熟的框架里写代码的一个好处是:你可以先假设你遇到的一切General的问题都已经有人遇到过了,而且很可能已经在框架层解决了。你只是得:
- 先意识到这个是General的问题。
- 形式化规范化这个问题。
- 然后用正确的姿势Google一下看看有没有人已经解决了。
比如代码10中的特定方法的性能问题,JDK已经意识到这个问题并且帮你解决了,有个专门的无方法接口叫RandomAccess用来标识一个List的get方法的时间复杂度是不是O(1)或比随机多次get快(详参文档)。那么代码中就可以用这个接口做为判断标准:
public static <T> List<T> except(List<T> list, List<Integer> indexes) {
final Set<Integer> indexesSet = new HashSet<>(indexes);
final IntStream indexesToSelect = range(0, list.size())
.filter(i -> !indexesSet.contains(i));
if (list instanceof RandomAccess) {
return indexesToSelect.mapToObj(list::get)
.collect(toList());
} else {
final List<T> accessList = new ArrayList<>(list);
return indexesToSelect.mapToObj(accessList::get)
.collect(toList());
}
}
代码 11
当然,这个代码正确工作的前提是,那个自己实现了一个List接口的人,也知道正确地使用RandomAccess接口。
好了,代码8到代码11展示了如何充分使用Java框架来解决这个问题。但是不幸的是,有些代码变得更恶心了(脸好疼)。每种方式都有自己的优劣,应当在使用的时候根据实际需要选择合适的方案。
LinkedList vs ArrayList
以上我们分析过参数的具体类型会对函数性能产生的影响。但是还没有具体讨论过以上代码3至代码9中所创建的临时List对象的选择问题。有心的人可能已经发现,有的用的是ArrayList有的用的是LinkedList。那么用得对吗?更进一步,什么叫用对?
Java自带了这两个主要的List的实现。从图1中可以看出他们在性能上的差别。理论上,我们可以根据自己的使用方式,根据是get操作多还是add/remove操作多来决定是用LinkedList还是用ArrayList。这是我们以上分析的主要依据,如果你Google网上的类似问题,这也是大家的建议。
但是问题是,这个依据对吗?add/remove多的时候,用LinkedList就一定好吗?还有什么其它会影响性能的因素呢?
CPU缓存命中率
CPU缓存命中率主要取决于:所需要访问的数据的大小,在内存中的分布及最重要的访问模式。那么具体到这个函数的CPU缓存命中率,主要受List本身(不包括各个List项T本身)在内存中的分布的影响。请试着想象一下他们两者在内存中的分布情况。大体会如下两图所示。
ArrayList内存分配示意图:
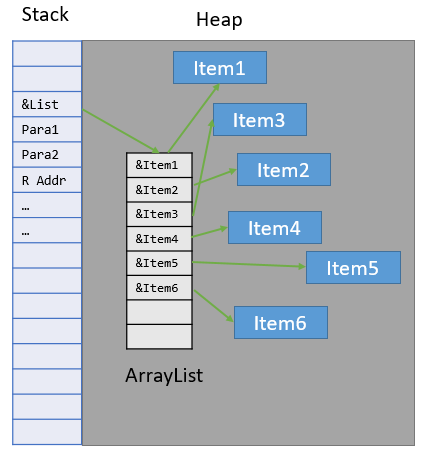
图 4
LinkedList内存分配示意图:

图 5
所以最糟糕的情况会是什么样的呢?你每次访问的LinkedList中的一个Node都Miss CPU的所有一、二、三级缓存。当然实际一般不会这么糟糕,但是绝对比ArrayList要糟糕。缓存不命中的后果就是从内存中读取数据。从内存读又怎么了呢?我们得先看看CPU缓存的访问速度与内存访问速度的差距才能回答这个问题。
从下图可以看出各级缓存结构的访问延迟(Core i7):
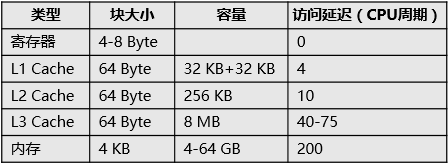
图 6
不难看出,根据问题规模的不同,内存访问会比CPU缓存慢3至50倍。那么这会对LinkedList的性能产生多大的影响呢?看访问延迟,估计有最大50倍性能差吧。不过性能上的事儿,必须要测试一下才知道。
在当前所实现的except函数的环境中,使用List的方式是创建一个默认大小的List,然后只增加不删除。我们就来模拟这个使用方式的下,不同List实现随着问题规模增长时性能的变化。结果如下图所示:
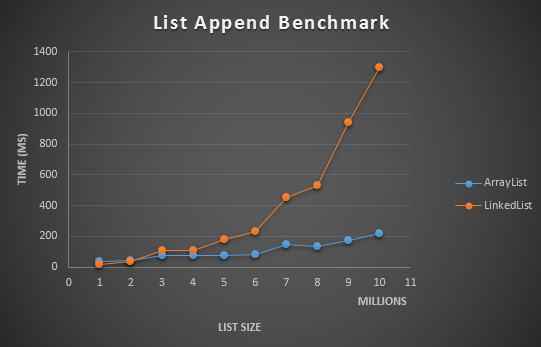
图 7
从图中不难看出,在问题规模比较小(小于一两百万数据)的时候,LinkedList有些许优势,而当问题规模大于五百万数据之后,由于数据局部性不足及CPU缓存容量的限制,LinkedList的性能下降得非常快。(据图可以估计出测试平台的CPU L3缓存大小,不是Core i7)
所以简单起见,你可以在所有的情况下都使用ArrayList,而不用太担心其插入、删除的理论性能比较低的事儿,其数据的局部性可以把大O的系数拉到很低。如果你的所预见的使用情况都只有不到几万数据量的话,用LinkedList也是不错的。当然其实这么少的数据,随便你用什么都可以。
上面这个结论对所有语言都是成立的。如果想深入了解,可以参考《Number crunching: Why you should never, ever, EVER use linked-list in your code again》。Bjarne Stroustrup也在其讲座中表达过同样的观点。
- 一直返回一种实现。
- 参数是什么类型,也返回什么类型。
- 不依赖任何List实现,让调用者根据结果自行构建List。
这样这个API的行为才是可控的。
Java有两个List实现!太漂亮了!
这里想说些题外话,我们如果退一步想想,上面代码复杂度问题的根源,其实是Java本身造成的。它自带了两个List的实现,于是有心的Java程序员们在写代码的时候,无时无刻不在想着:我这回应该用哪个实现呢?但是写C#、写Python什么的,你完全不用考虑这个问题。因为它们都只自带了一种List。因为LinkedList实在是没什么存在的必要。大概唯一的好处就是强迫一部分过于懒惰Java程序员们动动脑子。在某人不小心用了LinkedList,搞出个大大的性能问题,经过简单的分析就可以知道他写的那个List处理函数是多么的糟糕:一个不小心就把一个O(n)的函数用出了O($$n^2$$)的效果。自此LinkedList臭名昭著:性能杀手,效果拔群。于是JDK又引入了RandomAccess接口给这俩List擦屁股。说你们应该在写函数时候多多考虑一下非RandomAccess的List的感受嘛,你看我连接口都设计给你了,你不用?怪我喽?
如果对此有话题有兴趣,可以参看这个知乎问题下面的前五个回答。为什么那么多公司不用 .NET,而选择 PHP、JSP,是 .NET 有什么缺点吗?(这个问题虽然都没问Java,下面一群回Java的,呵呵)有个回答说的好:“.NET的问题就在于不能有效提高使用者的智商。”。Java不仅能,而且擅长。
想我写了快十年C#代码,其间几乎没有细想过List的实现是用数组更好还是用链表更好这个问题(毕竟也很少直接用List)。然而写Java的第一天我就意识到了。这个问题在Stackoverflow上很火。其中有一个排名不高的的回答有些碍眼。他说,LinkedList的作者Joshua Bloch(此人也是Effective Java和Java Concurrency in Practice两本书的作者),发过这样一条Twitter:
Does anyone actually use LinkedList? I wrote it, and I never use it.
看这语气,说像是在说:“我写了个用于IQ测试的Java类,你们通过了吗?”
通过以上二节的分析,主要并不是想解释如何在LinkedList和ArrayList之间做取舍,而是想说明一个事实:这些分析里有计算机本身的约束,也有不少是Java语言本身的一些细节,而不同的语言里,针对同一个问题会有不同的设计,不同的细节。如果不了解这些细节,并不能用合理的方式使用这门语言。而这些才是学习语言的难点。(PHP充斥着各种细节,所以成了最好的语言。)
掌握一门语言的法门,只能靠深学活用。能通过一个下午熟悉的,只有语法而已。而语法本身,常常并不是一门语言最重要的部分。甚至连重要都算不上。
接口隔离原则
前面讨论了Java里两个List的现实之间的取舍问题。一个终级解决办法就是不做取舍,让调用方自己去从结果集构建List,如果他需要一个List的话。意思就是说,我们不要求参数是List,也不返回一个List。而只使用完成这个函数所必须的操作(同时不损失性能)。这就是最小接口依赖原则的含义。哪么哪些接口是我们为了实现这个函数所必须要使用的呢?其实就一个:遍历。于是我们的except函数可以被简化成这样。
public Iterable<T> except(Collection<T> list, Set<Integer> indexes) {
}
indexes的参数变成了Set,也更符合这个操作本身的要求。直接返回一个Iterable,可以让使用者按自己的要求和具体环境选择下一步所需要的具体数据类型。我们来考虑如何实现这个函数,虽然从语法上,直接返回一个List是合法的,但是显然已经不符合我们的目标。所以,在这个版本的实现中,真的需要返回一个纯粹的Iterable才能达到效果。(思考题:如果有个子类重写了这个函数并返回一个具体的List,是否算违反了里氏代换原则?)
public static <T> Iterable<T> except(Collection<T> list, Set<Integer> indexes) {
final Iterator<T> iterator = list.iterator();
final Set<Integer> validIndexes = indexes.stream().filter(i -> i < list.size() && i >= 0).collect(toSet());
return () -> new Iterator<T>() {
private int cursor = 0;
@Override
public boolean hasNext() {
return cursor < list.size() - validIndexes.size();
}
@Override
public T next() {
while (validIndexes.remove(cursor))
move();
return move();
}
private T move() {
cursor++;
return iterator.next();
}
};
}
代码12
这还是用Java 8写的,都写了这么长,如果用老Java,代码将更长。解决长代码的方式也很简单,就是看看这个代码是不是承担了太多的责任。但是这么简单的操作,你说它承担了太多的责任,这不是搞笑么?但是它的确是的。它做的事情,至少可以分成这两步:
- 求indexes的补集。
- 按indexes选取元素。
于是这个操作可以被分解成这样:
public static <T> Iterable<T> except(Collection<T> list, Set<Integer> indexes) {
return select(list.iterator(),
range(0, list.size()).filter(i ->
!indexes.contains(i)).iterator());
}
public static <T> Iterable<T> select(Iterator<T> list, Iterator<Integer> orderedIndexes) {
return () -> new Iterator<T>() {
private int cursor = 0;
@Override
public boolean hasNext() {
assert list.hasNext();
return orderedIndexes.hasNext();
}
@Override
public T next() {
while (cursor < orderedIndexes.next()) {
cursor++;
list.next();
}
return list.next();
}
};
}
代码 13
情况看上去更糟糕了-_-,但是这个新的select函数在通用性上显然比except要高得多,它也可以被except之外的其它的集合操作函数所使用。其它的集合操作函数,只是需要先通过纯粹的数学运算计算出要提取的元素的位置,然后最后调用select函数。
但是,即使这样,这个3行的except,跟它所需要解决的问题相比,也还是没必要地复杂了。
Iterable vs List
使用Iterable相比使用List,除了缩小了接口依赖之外,其实还有几个的不小的好处。
- 延迟求值。意思是这个函数本身运行时间变成了O(1)。
- 内存占用从O(n)减小到了O(1)。因为只返回了一个Iterable,而没有返回任何数据。
但是这些好处不是没有代价的。使用Iterable也会带来几个不小的问题。
- 隐式依赖参数列表。
- 不可重复使用。
- 非线程安全。
- 由于3,所以不可并行化。
第一点很明显,就当成思考题吧。第二点给个使用环境当引子。
private static <T> void printTwice(Iterable<T> items) {
items.forEach(s -> System.out.println(s));
items.forEach(s -> System.out.println(s));
}
代码12和代码13与之前的代码相比,在上面的使用方式下会具有不同的结果。而这个结果是编码者不想看到的。(C#里近似的接口IEnumerable,由于合理的接口设计,没有这个问题。)
可并行性
对于性能要求比较高的环境,可代码本身的并行性也会一个重要的代码可用性及质量的考量。如果用Java 8的流实现,并且实现成纯函数,好处之一就是可以比较简单地支持多线程并行计算。基于代码10,可以通过一个函数完成并行化。如代码14所示:
public static <T> Collection<T> except(List<T> list, Set<Integer> indexes) {
return range(0, list.size())
.parallel()
.filter(i -> !indexes.contains(i))
.mapToObj(list::get)
.collect(toList());
}
代码 14
然而如果想把使用Iterator的代码并行化就没有那么轻松写意了。如果你有兴趣的话,可以写一个可并行化的Iterator试试。
Java vs .NET
写了12个版本的Java代码了,断断续续地花了好几天。代码越来越长,却始终找不到一个简洁、高效、灵活、可扩展的实现方式。想想就觉得火大。C#程序员可能早就憋不住了,这个问题的C#版实现方式不要太简洁。
public static IEnumerable<T> except<T>(IEnumerable<T> items, ISet<int> indexes)
{
return items.Where((t, i) => !indexes.Contains(i));
}
看着这代码,顿时觉得写代码还是那么的美好,而且它具有一切好处:线性时间、延迟求值、参数无关、最小依赖等。写法也简单到我都不屑于提取出来一个函数。想想真心疼Java程序员们。不过或许这就是Java提高使用者智商的方式呢!再说了,我们都知道语言层面的东西都是不重要的。对吧?(这么想心里会舒服些,毕竟我也在写Java。)
如果你在写C#,可能不自觉地就免费地获得了不少的好处,这是一种幸福。但是这并不表示应该在写代码的时候可以无视上述的那些潜在问题。否则就成了Java程序员所鄙视的那种只会拖拖控件的码农界食物链末端生物。
.NET自动地为程序员们做了很多事情,而且做得很出色。但是做得太好,好到程序员代码写烂了它都能工作得还不错,结果不小心把不少.NET程序员都给惯傻了,傻到出点儿问题都不知道怎么下手处理,然后还反过来骂.NET是垃圾。而Java程序员从一上手写代码开始,就要开始解决这样那样的问题,水平慢慢地就被迫堆高了。其后果就是.NET始终被Java压制,这大概是微软始料未及的吧。
那些事儿
在引言里说过,这篇文章只是想说说那些显而易见的事儿。然而一千个人眼中有一千个哈姆雷特。所以我担心不说得清楚些,还是会有人不知道我在说在什么。本文的目的不是解释这个except函数在Java里怎么写也不是为了展示Java里多样的写法。本文要说的那些事是:
- 编程没有简单问题,再简单的问题都有多种解法适用于不同的环境。
- 学习一门语言从来不是一个简单的事儿。但是学习到这个语言的公共部分是个很简单的事儿(就像大牛们宣扬的,你基本功扎实的话,一两天的事儿)。
- 学习一门语言到公共部分就可以解决你工作上的所有问题,而且在这个层次,的确可以说用什么语言写代码都是无所谓的。(因为你总是可以自己搞定剩下的语言特定部分——大凡都通过重新造轮子的方式。)
- 深入学习一个语言,从来不是一个简单的事儿。(那怕简单如Java都是这样,我也没有深入学习过Java,我只是简单了解了一下JCF,然后看了点Best Practice而已。)
- 在你把一个语言学到一定深度之前,你可能会看到一些代码看不太懂。这个时候正确的积极的心态是承认自己的水平不够,而不是抱怨这个代码的可读性太差、搞得别人都看不懂。
- 最好等真精通了一门或几门语言之后再谈论什么一通百通,否则对于个人成长而言遗患无穷。(以Java为类,感觉对java.lang,java.util,java.io包里的所有最新的类的所有方法都了解并能合理使用才能算熟悉级别的吧。)
- 选择一门表达力强并且适用你个人理解力极限的编程语言,可以提高效率、节省时间、延长生命、早下班、赚更多的钱。(没最后两点大概没有人关心吧。)
- 公司不幸用了Java你也得适应。
参考书目
Cay S. Horstmann, Gary Cornell. Core Java 2, Volume II – Advanced Features (《Java2核心技术 卷II:高级特性》)
Richard Warburton. Java 8 Lambdas: Functional Programming for the Masses (《Java 8 函数式编程》)
Joshua Bloch. Effective Java Second Edition (《Effective Java中文版》)
Randal E. Bryant, David R. O’Hallaron. Computer Systems – A Programmer’s Perspective Third Edition (《深入理解计算机系统》)
Thomas H. Cormen, Charles E.Leiserson, Ronald L. Rivest, Clifford Stein. Introduction to Algorithms Second Edition(《算法导论》)
Donald E. Knuth. The Art of Computer Programming Vol 1: Fundamental Algorithms Third Edition (《计算机程序设计艺术 卷1:基本算法》)